Nick Sieger created graphs of the grammars for Ruby, Java 1.5, and Javascript. The Ruby grammar was created from parse.y from the original C implementation. I'm not sure what he used for the other two, i.e. whether they are from "real" grammars.
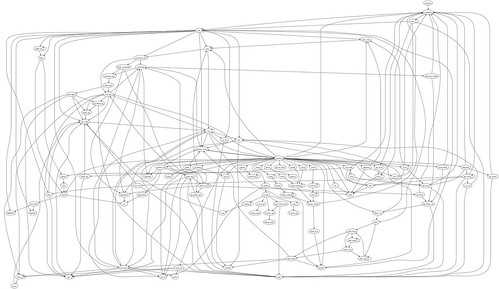
Nick notices the primary node as the center of complexity for the Ruby grammar. I wonder how a more incrementally derived, top-down parser might distribute that complexity, e.g. one built for a "packrat parser".

No comments:
Post a Comment